Table des matières
Introduction – quand les données racontent une histoire
Imaginez‑vous responsable marketing : vous désirez savoir si l’investissement publicitaire mensuel influence directement le chiffre d’affaires. Ou encore enseignant : vous cherchez à vérifier si le nombre d’heures d’étude prédit la note finale. Dans ces deux cas, un simple graphique – le diagramme de dispersion (ou scatter plot) – transforme une forêt de chiffres en une histoire limpide et convaincante.
À retenir : un scatter plot affiche deux variables quantitatives sur deux axes perpendiculaires, révélant instantanément corrélations, tendances et anomalies.
1. Qu’est‑ce qu’un diagramme de dispersion ?
Un diagramme de dispersion est un nuage de points où chaque point représente une observation caractérisée par deux variables numériques : l’une placée sur l’axe X, l’autre sur l’axe Y. Observer la forme du nuage permet d’évaluer l’existence, la direction, la force et la nature d’une relation (linéaire, non linéaire, inexistante).
1.1 Pourquoi l’utiliser ?
- Vérifier des hypothèses : plus la température augmente, plus les ventes de glaces grimpent.
- Détecter des valeurs atypiques (outliers) susceptibles de biaiser une analyse.
- Préparer une modélisation : corrélation de Pearson, régression linéaire, modèles non paramétriques.
- Communiquer visuellement : visualisation de données à un public non technique.
1.2 Histoire et évolution
Les premiers nuages de points apparaissent au XVIIIᵉ siècle avec John Herschel pour étudier l’astronomie. Au XXᵉ siècle, ils deviennent incontournables en contrôle qualité (méthode Six Sigma) puis en data science moderne grâce aux bibliothèques Python/R, et plus récemment aux visualisations interactives (Plotly, Vega‑Lite).
2. Construire un nuage de points pas à pas
2.1 Jeu de données d’exemple
| Obs. | Heures d’étude (X) | Note (%) (Y) |
|---|---|---|
| 1 | 1 | 48 |
| 2 | 2 | 55 |
| 3 | 3 | 63 |
| 4 | 3 | 65 |
| 5 | 4 | 70 |
| 6 | 5 | 78 |
| 7 | 6 | 82 |
| 8 | 7 | 86 |
| 9 | 8 | 88 |
| 10 | 9 | 91 |
Voici le diagramme de dispersion basé sur les 10 observations. Tu peux l’importer directement dans Canva ou tout autre outil :
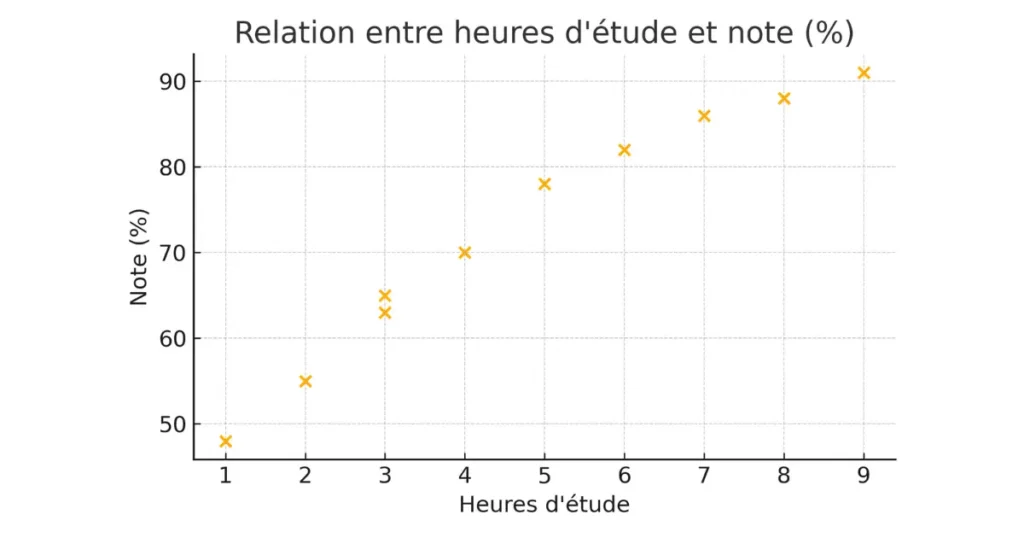
Lecture rapide : on voit une tendance clairement positive : plus les heures d’étude augmentent, plus la note progresse, ce qui illustre la corrélation attendue entre effort et performance
2.2 Étapes clés
- Collecte & nettoyage des données : supprimer doublons, corriger erreurs, gérer valeurs manquantes.
- Choix des axes : variable explicative sur X, variable réponse sur Y (respectez l’ordre logique cause → effet).
- Traçage : outil (Excel, Google Sheets, Python + Matplotlib/Seaborn, R + ggplot2, Power BI).
- Personnalisation : titre clair, étiquettes explicites, couleur & taille des points, quadrillage discret.
- Analyse visuelle : forme générale, pente, dispersion, outliers, sous‑groupes éventuels.
2.3 Exemple de code Python
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data = pd.read_csv("notes_etudes.csv")
plt.figure(figsize=(7,5))
ax = sns.scatterplot(data=data, x="heures", y="note", hue="section", s=80, alpha=0.8)
ax.set_title("Heures d’étude vs Note finale")
ax.set_xlabel("Heures d’étude")
ax.set_ylabel("Note (%)")
plt.show()
Tip : ajoutez sns.regplot pour superposer une ligne de régression et plt.annotate pour pointer les outliers.
3. Personnalisation et design accessible
| Élément | Bonne pratique | Pourquoi ? |
|---|---|---|
| Couleur | Palette contrastée & daltonien‑friendly (Viridis) | Accessibilité WCAG 2.1 |
| Taille des points | Variez selon importance ou valeur supplémentaire | Encodez une 3ᵉ variable |
| Transparence | alpha=0,4 pour gros volumes | Limite la saturation |
| Forme des points | Différenciez des catégories nominales | Comparez des groupes |
| Légende | Position claire, police ≥ 10 pt | Lisibilité immédiate |
Astuce UX : dans un dashboard, coupez le scatter plot en facettes (small multiples) pour comparer des sous‑ensembles sans surcharger l’affichage.
4. Interpréter un diagramme de dispersion
4.1 Typologies de relations
- Corrélation linéaire positive : nuage ascendant ; plus X ↑, plus Y ↑.
- Corrélation linéaire négative : nuage descendant ; X ↑, Y ↓.
- Absence de corrélation : nuage informe ; variables indépendantes.
- Relation non linéaire : forme courbe (log, exp, sigmoïde).
- Hétéroscédasticité : variance de Y change avec X (entonnoir).
- Tendance segmentée : rupture de pente ; envisagez une régression piecewise.
4.2 Lire au‑delà des apparences
- Clusters cachés : coupez la couleur par catégorie pour déceler des groupes.
- Influence des outliers : un seul point extrême peut masquer une corrélation réelle ou en créer une artificielle.
- Corrélation spurious : deux variables peuvent sembler liées parce qu’elles évoluent avec le temps (effet calendrier) ; contrôlez la variable temporelle.
Attention ! Corrélation ≠ causalité : un scatter plot révèle une association mais ne prouve pas qu’une variable cause l’autre. Expérience contrôlée ou analyse de causalité (DAG, randomisation) requise.
5. Indicateurs statistiques à connaître
| Indicateur | Rôle | Interprétation rapide |
|---|---|---|
| r de Pearson | Force & direction du lien linéaire | r ≈ +1 lien + fort ; r ≈ –1 lien – fort ; r ≈ 0 lien faible/absent |
| ρ de Spearman | Corrélation de rangs (non paramétrique) | Robuste aux outliers, aux relations monotones non linéaires |
| τ de Kendall | Alternative à Spearman, petits échantillons | Prend en compte toutes les paires concordantes/discordantes |
| p‑value | Tester la significativité statistique | p < 0,05 → lien non dû au hasard (α = 5 %) |
| R² | Part de variance expliquée par X | 0 ≤ R² ≤ 1 ; plus proche de 1, meilleur modèle |
| IC 95 % de la pente | Intervalle de confiance de la régression | Si 0 ∉ IC, relation significative |
6. Applications métiers approfondies
6.1 Étude de cas marketing : ROI publicitaire
Problème : déterminer si l’augmentation du budget social ads accroît le nombre d’abonnements mensuels.
- Données : 24 mois, variable X = budget (k€), variable Y = abonnements (k).
- Scatter plot : nuage ascend.
- Régression linéaire : pente = 0,43 (IC 95 % [0,29 ; 0,55]) → chaque 1 k€ investi rapporte ~430 abonnés.
- Décision : maintenir le budget jusqu’au seuil de saturation identifié (courbe plate).
6.2 Autres secteurs
- Qualité industrielle : diamètre du trou vs couple de serrage.
- Santé publique : relation IMC–coût médical annuel.
- Finance : volatilité vs rendement (effet risque/rentabilité).
- Éducation : temps de révision vs réussite.
- Environnement : CO₂ moyen vs température globale.
7. Outils et bibliothèques recommandés
| Logiciel | Niveau | Avantages | Limites |
|---|---|---|---|
| Excel/Sheets | Débutant | Ubiquitaire, facile | Personnalisation limitée, rép. manuelle |
| Tableau | Intermédiaire | Interactif, drill‑down | Licence payante |
| Power BI | Intermédiaire | Intégration MS, DAX | Learning curve |
| Python (Matplotlib, Seaborn, Plotly) | Avancé | Flexible, code réplicable, open source | Nécessite script & base Python |
| R (ggplot2, plotly) | Avancé | Grammaire graphique élégante | Syntaxe R spécifique |
| Vega‑Lite | Intermédiaire | JSON déclaratif, web | Configuration initiale |
Bon à savoir : Plotly Express permet de passer du scatter plot 2D au 3D ou au bubble plot avec un seul paramètre (
size).
8. Erreurs courantes & bonnes pratiques
- Mettre un ratio d’axe inadapté → fausse impression de pente.
- Oublier les unités → confusion interprétative.
- Surpeupler le graphique → préférer l’hexbin ou la densité pour > 5 000 points.
- Ignorer la saisonnalité → spurious correlation.
- Tromper avec la transparence → masquer les clusters.
Checklist avant publication
- Axes étiquetés avec unité ?
- Titre informatif ?
- Légende lisible ?
- Outliers annotés/justifiés ?
- Couleurs accessibles ?
9. Alternatives et variations
| Variant | Description | Cas d’usage |
|---|---|---|
| Bubble plot | Ajoute taille (3ᵉ var.) | Poids du client, CA, satisfaction |
| Scatter 3D | Ajoute profondeur (3ᵉ axe) | Chimie : pression‑température‑volume |
| Stripplot/Swarmplot | Dispersion une var. + caté | Bioinformatique : expression gène |
| Hexbin | Grille hexag. densité | > 50k points GPS |
| Contour/Kernel density | Iso‑densité | Vision machine : détection foule |
10. Quiz interactif – testez vos connaissances
- Quel coefficient évalue une relation monotone non linéaire ?
- a) r de Pearson
- b) ρ de Spearman
- c) R²
- L’hétéroscédasticité se traduit par …
- a) un nuage symétrique
- b) une variance croissante ou décroissante avec X
- c) des données manquantes
- Vrai ou faux : un R² élevé garantit une causalité.
- Quel outil open source Python permet une visualisation interactive sans code JS ?
- a) Matplotlib
- b) Plotly Express
- c) Excel
Réponses : 1‑b, 2‑b, 3‑Faux, 4‑b.
11. FAQ : Diagramme de dispersion
Comment créer un diagramme de dispersion dans Excel ?
Sélectionnez vos deux colonnes › Insertion › Graphiques › Nuage de points › Personnalisez titre & axes.
Quelle différence entre corrélation et régression ?
La corrélation mesure l’intensité d’un lien ; la régression fournit une équation prédictive et permet d’estimer l’effet d’une variable sur l’autre.
Peut‑on tracer un scatter plot avec des variables qualitatives ?
Non ; il faut encoder ces variables (one‑hot, label encoding) ou utiliser un graphique adapté (boîte à moustaches, barres).
Comment gérer des valeurs aberrantes ?
Repérez‑les visuellement, vérifiez l’origine (erreur de saisie ? phénomène rare ?) puis décidez de les garder, de les transformer (log), ou de les exclure avec justification.
Quels logiciels gratuits recommandez‑vous ?
Python (Matplotlib, Seaborn, Plotly), R (ggplot2, plotly), Google Sheets, LibreOffice Calc.
Quel format utiliser pour publier un scatter interactif sur le web ?
HTML + JS (Plotly), Jupyter Notebook, ou iframe Tableau Public.
12. Conclusion
Le diagramme de dispersion est une arme visuelle simple mais puissante : en un coup d’œil, vous révélez la dynamique cachée entre deux variables, détectez les anomalies et posez les bases d’analyses prédictives plus avancées. Que vous soyez analyste, ingénieur qualité, data scientist ou étudiant, maîtriser cet outil est indispensable pour transformer des données brutes en décisions éclairées.
Pour aller plus loin, explorez les modèles non linéaires (régression polynomial, forêt aléatoire) et intégrez vos scatter plots dans des tableaux de bord interactifs pour une prise de décision en temps réel.